
Predicting Voter Affiliation using Machine Learning Classifiers in Python
In this notebook I'll go through some work I did for a recent political campaign where we needed to predict the affiliation of voters whose ballots were invalidated. We wanted to sue to restore the validity of many ballots - but obviously we wanted to prioritize those ballots who we had good reason to think voted for our candidate.
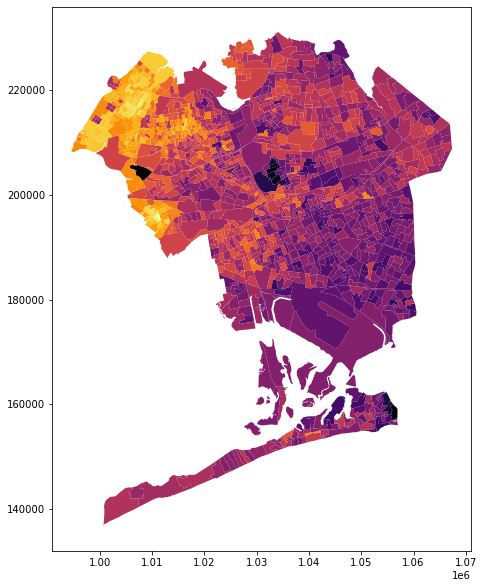
Our candidate being young, progressive, and Latin american, we had good reason to expect that age, ethnicity, and geography (ie more left-leaning neighorhoods) were reasonable factors to influence voter affiliation. In the following map, brighter yellow areas are the strongest for our candidate relative to the primary opponent, and dark purple areas are strongest for the primary opponent relative to our candidate.
However, this demographic and geographic information wasn't all we had to go off of - we actually conducted a poll of some of these voters and determined whether or not they voted for our candidate.
Using this voting data, the aforementioned demographics and geographical data, I trained a popular machine learning classification model, Random Forest, so that we could predict the affiliation of the rest of the voters whose ballots were invalidated, and hence prioritize them in our legal case.
Importing Packages¶
We'll proceed with building our model by importing pandas, numpy, our model, parameter tuning tools, and metrics from sklearn.
import pandas as pd
pd.options.mode.chained_assignment = None
import numpy as np
from sklearn.model_selection import train_test_split
### MODELS TO USE
from sklearn.ensemble import RandomForestClassifier
# PARAMETER TUNING / CROSS VALIDATION TOOLS
from sklearn.model_selection import GridSearchCV
### MODEL EVALUATION METRICS TO USE
from sklearn.metrics import mean_squared_error
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
Loading Data¶
Next, we'll load our data using pandas as the dataframe df. The data has already been scaled and stored in the model_variables_pred.csv file.
df=pd.read_csv('model_variables_pred.csv')
df.head()
Each row in this dataframe corresponds to an individual voter (anonymized).
The columns correspond to the demographic and voting information provided above; Candidate denotes the affiliation of the voter, we have our age and ethnicity, columns age_scaled and latinx_score, and finally we have the column weight.
The weight column is represented by the map at the top of the notebook, and indicates the preferences of voters overall within the home Election District of the corresponding voter, for our candidate relative to the primary opponent.
A little bit more about the visualization will be helpful here; I used the geographic data analysis package geopandas to load the file EDs_weight.shp, which is a shapefile indicating the weight scores for each Election District.
import geopandas as gpd
EDs_weight = gpd.read_file('EDs_weight.shp')
EDs_weight.to_crs(epsg=4326);
plt.clf()
EDs_weight.plot('weight', figsize=(10,10),cmap='inferno')
plt.show()

A couple notes about the above code: after loading the shapefile as a geodataframe, we have to set the coordinate system, which in this case is EPSG:4326. These coordinates are visible on the edges of the above map.
In this map, brighter yellow areas are the strongest for our candidate relative to the primary opponent, and dark purple areas are strongest for the primary opponent relative to our candidate. This is the information encoded into the weight column; each voter's home district gets a score, called weight, and this score is assigned to them in the weight column within the dataframe df.
Setting Prediction and Target Variables and Filling in Missing Data¶
Let's proceed by setting our prediction variables X and target variable y to be the columns corresponding to age, ethnicity, weight, and candidate preference respectively:
X = df[['age_scaled', 'latinx_score', 'weight']]
y = df['Candidate']
Next we'll fill any missing data:
y = y.fillna(value=0)
mean_list = X.mean().tolist()
X['age_scaled']=X['age_scaled'].fillna(value=mean_list[0])
X['latinx_score']=X['latinx_score'].fillna(value=mean_list[1])
X['weight']=X['weight'].fillna(value=mean_list[2])
Split into Train and Test sets¶
Now that our data is cleaned and split into Predictor and target variables X and y, we can split our data into training and test sets using a 40% holdout size for the test set:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 42)
Hyperparameter Tuning¶
Instead of jumping right in to training our model using the RandomForestClassifier(), we'll set up a parameter grid param_grid_rf so that we can optimize our model using Hyperparameter Tuning.
def round_to_int(x):
return int(np.rint(x))
num_cols = len(X_train.columns)
n_est_space=np.array([round_to_int(x) for x in np.logspace(1, 1.5, num = 20)])
max_feat_space=np.arange(round_to_int(np.sqrt(num_cols) / 2), round_to_int(np.sqrt(num_cols) * 2) + 1)
param_grid_rf = {'n_estimators': n_est_space, 'max_features': max_feat_space}
Training our model¶
Now with our parameter grid set up, we'll use GridSearchCV() to tune parameters and fit our Random Forest classifier rand_forest:
rand_forest = RandomForestClassifier()
rand_forest_cv = GridSearchCV(rand_forest, param_grid_rf, cv = 5, iid=True)
rand_forest_cv.fit(X_train, y_train)
Now we can see our optimal parameters and accuracy:
print("Tuned Random Forest Parameters: {}".format(rand_forest_cv.best_params_))
print("Tuned Random Forest Accuracy: {}".format(rand_forest_cv.best_score_))
Let's also check out our classificication report:
y_pred_rf = rand_forest_cv.predict(X_test)
print(confusion_matrix(y_test, y_pred_rf))
print(classification_report(y_test, y_pred_rf))
Worth noting is that I checked the performance of other popular classifiers, such as K-Nearest Neighors, Logistic Regression, and Support Vector Classification, but (somewhat unsurprisingly), Random Forest performed the best.
Conclusion¶
We trained a Random Forest classifier on our voting, demographic, and geographic data to predict voter affiliation. Our accuracy is about 73% and we have an f1 score of 0.63. While not perfect, our model undoubtedly helped us determine which voters to prioritize in our legal case.